毕设算是告一段落,里面用了一点点人脸识别,其实完全是OpenCV自带的,源自两篇论文:
P. Viola and M. Jones.Rapid object detection using a boosted cascade of simple features.
R. Lienhart and J. Maydt. An Extended Set of Haar-like Features for Rapid Object Detection.
Paul Viola 和Miachael Jones等利用Adaboost算法构造了人脸检测器,称为Viola-Jones检测器,取得很好的效果。之后Rainer Lienhart和Jochen Maydt用对角特征,即Haar-like特征对检测器进行扩展。OpenCV中自带的人脸检测算法即基于此检测器,称为“Haar分类器”。
Haar-like特征可由下图表示:

每个特征由2~3个矩形组成,在这些小波示意图中,浅色区域表示“累加数据”,深色区域表示“减去该区域的数据”。分别检测边界、线、中心特征,这些特征可表示为:
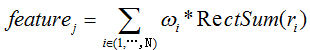
其中, wi 为矩形的权,RectSum(ri) 为矩形 ri 所围图像的灰度积分, N 是组成 featurej 的矩形个数。
Adaboost是一种基于统计的学习算法,在学习过程中不断根据事先定义的各个正例和反例的特征所起的效果调整该特征的权值,最终按照特征的性能的好坏给出判断准则。
其基本思想是利用分类能力一般的弱分类器通过一定的方法叠加(boost)起来,构成分类能力很强的强分类器。Adaboost训练强分类器的算法描述如下:
给定一系列训练样本 (x1,y1),(x2,y2),...(xn,yn),其中 xi 表示第 i 个样本, yi=1 时为正样本(人脸), yi=0 表示负样本(非人脸)。对每个特征 featurej ,训练一个弱分类器 hj(x),之后对每个特征生成的弱分类器计算权重误差:

将具有最小误差 ej 的分类器叠加到强分类器中,并更新训练样本的概率分布:
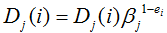
其中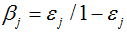 ,ei=0 表示样本 xi 被正确分类,否则 ei=1 表示未被正确分类。最终构成强分类器:
,ei=0 表示样本 xi 被正确分类,否则 ei=1 表示未被正确分类。最终构成强分类器:

其中 b 为设置的阈值,默认为0。
级联强分类器示意图如下:

Viola-Jones检测器利用瀑布(Cascade)算法分类器组织为筛选式的级联分类器,级联的每个节点是AdaBoost训练得到的强分类器。在级联的每个节点设置阈值 b,使得几乎所有人脸样本都能通过,而绝大部分非人脸样本不能通过。节点由简单到复杂排列,位置越靠后的节点越复杂,即包含越多的弱分类器。这样能最小化拒绝图像但区域时的计算量,通知保证分类器的高检测率和低拒绝率。例如在识别率为99.9%,拒绝率为50%时,(99.9%的人脸和50%的非人脸可以通过),20个节点的总识别率为 :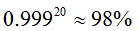
而错误接受率仅为: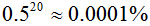
分享到:




相关推荐
该文件包含Adaboost训练的图片文件和训练后的数据,可以直接使用。使用参考链接:http://blog.csdn.net/oemt_301/article/details/78776159
基于opencv+vc6.0的人脸检测,算法是AdaBoost
使用Python,Opencv的Adaboost,人脸识别,Python基于OpenCV库Adaboost实现人脸识别功能详
基于OPENCV的人脸识别项目-python -包括基础人脸 -动态人脸识别-人脸勾画等等等等
基于opencv的人脸识别,是用visual studio 2010开发的。。是学习opencv的好例子。用的是opencv2.2.下载后配置下vc++目录和连接器输出即可。。
这是利用opencv实现的基于haar特征的adaboost人脸检测算法,使用VS平台,亲身实践可以使用,将图片放在该文件夹目录下,修改代码中图片名称与你所放图片名称一致就可以对图片中的人脸进行检测。使用时,确保你安装了...
人脸检测步骤:打开摄像装置,读取opencv自图,带haar分类器,截取每一帧的照片,保存人脸进行预处理,代码简洁明了,适合借鉴学习。
OpenCV-Python 4.5.4新增的人脸识别应用 检测模型: yunet.onnx 识别模型:face_recognizer_fast.onnx
c++全套源码,基于openvino2022.1.0.643和opencv4.6.0实现 内含依赖的预训练模型和测试图片,直接运行即可查看识别结果。 person-vehicle-bike-detection-crossroad-1016 vehicle-attributes-recognition-barrier-...
OpenCV人脸识别实例源码-3.0 OpenCV人脸识别实例源码-3.0
OpenCV人脸识别文件haarcascade-frontalface-default.xml
OpenCV利用级联的haar分类器进行人脸识别
基于Qt和openCV人脸识别程序(linux-ubuntu系统下).zip 基于Qt和openCV人脸识别程序(linux-ubuntu系统下).zip 基于Qt和openCV人脸识别程序(linux-ubuntu系统下).zip 基于Qt和openCV人脸识别程序(linux-ubuntu系统下)....
基于Haar+Adaboost人脸识别 使用python+cv2实现 具体算法原理待日后整理说明 先上传可实现代码,有需要的自行前往下载。 代码运行环境: jupyter notebook+python3
最后,通过上述理论学习,基于OpenCV,在Visual Studio 2012开发环境下,利用ORL人脸数据库,分别对上述算法进行了算法实现和实验验证,并且在最后创建了一个基于特征脸的实时人脸识别系统,该系统可以实现人脸的...
OpenCV-python haar分类器人脸识别 详细介绍 https://gitee.com/Wind_to_valley/open-cv-face-recognition
基于OpenCV的人脸识别门禁系统的开发一般包括以下步骤: 1. 硬件准备:准备一台安装摄像头的计算机或嵌入式设备作为门禁终端。 2. 安装OpenCV:在门禁终端上安装OpenCV库,用于进行人脸识别和图像处理。 3. 数据...
基于OpenCV和Adaboost算法的人脸检测
OpenCV-Python-Toturial-中文版.pdf
HAAR基于摄像头的人脸识别门禁模拟程序_人脸识别_OPENCV_C++